
A classic example of such an extensive amount of available categories are projects which want to include a wide range of species, e.g. for biodiversity monitoring. But also beyond the natural world, there are many appliances of a large number of classifications in Citizen Science.

Making a large number of data categories searchable in a Citizen Science App
There is a vast repository of data objects available that have been built by the community over the last decades: WikiData. WikiData is the underlying layer of Wikipedia, providing a data object for every Wikipedia entry with classifications, localized names and representative images. Not only can that huge data repository be accessed via an online connection, it furthermore provides the possibility of being included in a Citizen Science App.
With the SPOTTERON Taxonomy Service, we have implemented a suggestion input field, which provides instant name-matching with a user's input on the fly and makes the output selectable as a category in the App. Users can start typing, and the App delivers a suggestion list based on that input to choose from. With more and more letters, these suggestions get refined instantly, narrowing the list of available choices on the go.
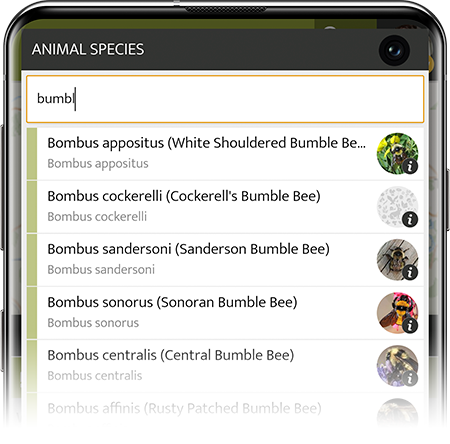
An example from a biodiversity monitoring App
In the case of a biodiversity Citizen Science App, these suggestions would be all kinds of bumblebee species and the "Bombus" genus as a parent when a user starts typing "bumb" in the suggestion input field. The users now can simply select the category they want to add.
Not only for biodiversity but for describing our world
But the massive WikiData database is not only restricted to biodiversity or species. As a reliable backbone, it also allows the implementation of other kinds of category trees. Everything organized into taxas as a classification system and present in the WikiData set can be used as a source for matching user inputs with category suggestions, from cultural or historical references to astronomical objects or even, for example, all the world's musical instruments.
Data interoperability for Community Science
WikiData also provides additional cross-references for data categories IDs of other systems and, in terms of biodiversity data, maintains an index for species IDs from a wide range of platforms - from TreeOfLife to GBIF. The additional available data adds a layer of data interoperability and allows further data exchange with other ID schemes.
Data inputs in local languages
One crucial aspect of Community Science Apps is language compatibility. Inclusiveness starts by making it possible for the local population to participate in a Citizen Science project in their regional language. WikiData includes not only English terms but also localized translations for many languages, making it possible for Citizen Scientists to add data even if someone speaks only their native tongue.
The importance of local languages is especially true when categories have different name schemes like every species. Plants, animals, and fungi have scientific names and a wide range of common names. In most cases, only the common names are familiar to participants, making localized species names a vital ingredient in a Citizen Science App. With the SPOTTERON Taxonomy Service, using local languages, scientific names, and common names along with each other is now possible for Citizen Science to collect records of biological species.

The technology behind the SPOTTERON Taxonomy Service
For matching user inputs with a vast database without delays in an interactive App, a specialized ICT infrastructure is necessary. The Service is running on its own servers on the SPOTTERON Cloud, being just responsible for that single task.
We maintain copies of the WikiData database for all included categories in Citizen Science Apps on that infrastructure, which is indexed by specialized software that empowers data matching on a time-crucial basis and which is able to handle millions of records almost in real-time. This infrastructure is the core of making such data matching possible, and as part of the Service, we also take care of the maintenance of all included technologies.
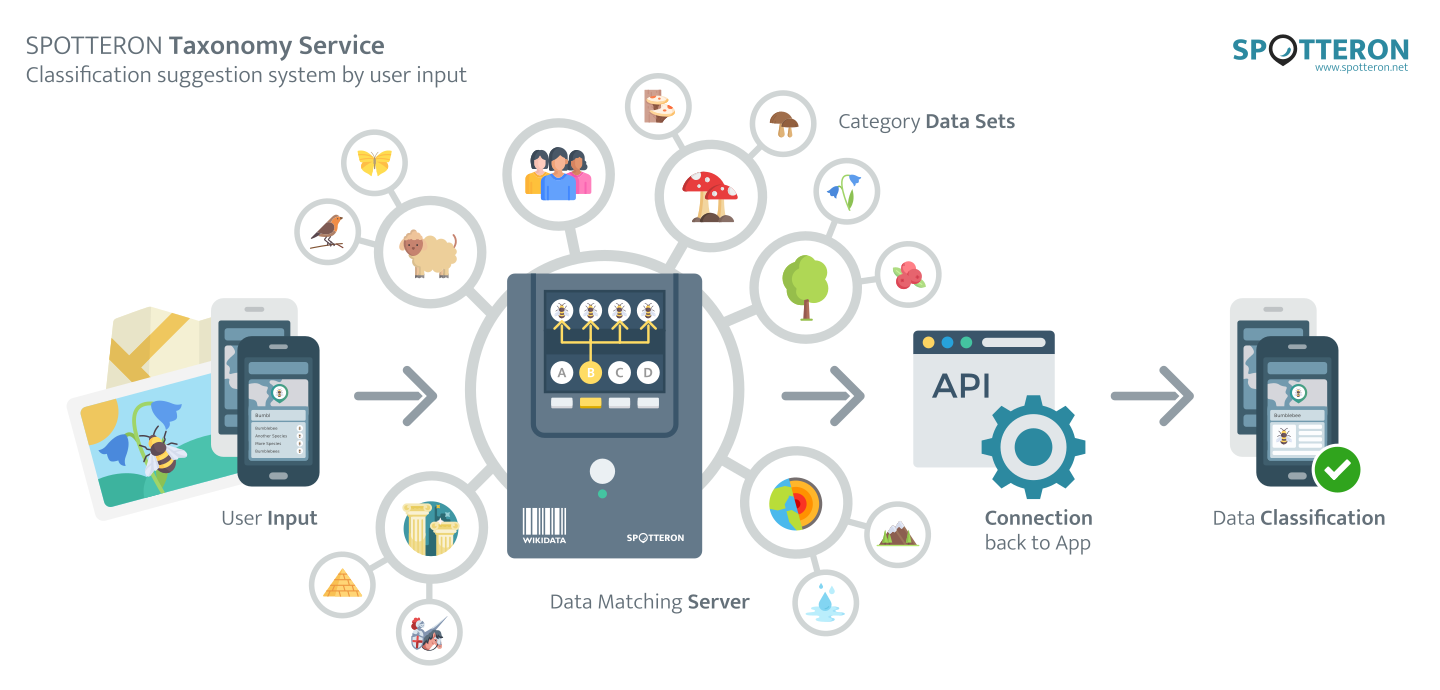
Utilizing data input matching in Citizen Science Apps
If a project needs to include an extensive range of data categories, the SPOTTERON Taxonomy Service stands ready to be used. Our team will support projects which want to integrate the Service in their own Citizen Science Apps from the start.
If you are interested in utilizing the SPOTTERON Taxonomy Technology in your Citizen Science App, or want a live demonstration, please send us a quick email: